7 Tips for Using Technology to Find the P-Value in StatCrunch
1. Sort by “All” or “Mean” instead of “Median”. The median is a useful statistic to describe how far an item or group falls in the middle of all values in a list, but it should be avoided when looking for p-values since it has no predictive power, meaning it cannot help us know if one value is more likely than another.
2. Look at “Largest” and “Smallest”. These statistics give us an idea of where the median would fall, taking into account all values in between.
3. Look at individual lists and try to find outliers: observations that are much higher or lower
The Difference between a Statistical Test and a Statistical Method
StatCrunch is a popular statistical software that can be used to easily and thoroughly break down data. It is important to use the right tools for your problem, if you are trying to find p-values in a dataset. This blog will discuss some of the tips that can be applied so that you can get the most out of your analysis.
1. Sort by “All” or “Mean” instead of “Median”. The median is a useful statistic to describe how far an item or group falls in the middle of all values in a list, but it should be avoided when looking for p-values since it has no predictive power, meaning it cannot help us know if one value is more likely than another.2. Look at “Largest” and “Smallest”. These statistics give us an idea of where the median would fall, taking into account all values in between.3. Look at individual lists and try to find outliers: observations that are much higher or lower
The Difference between a Sample and a Population
A sample is taken from a population, or group of people. The data in the sample is representative of all members of that group, but it does not include every single member. When analyzing a sample, we can get an idea of what the typical value for that variable would be.
A population can also be described as every person in a country or region, for example. For example, in the United States there are some people who make less than $25,000 and others who make more than $100,000. This means that our US population has both extremes represented in it and we cannot say anything about what the average income is without knowing how many people are in each category.
In statistics when we want to know about the typical value for something within a population and we do not have access to the entire set of data with the same variables included, we will use a sample to see if our theory holds true or not.
How Does Variance Calculate?
The variance is a way to measure the dispersion of a set of data. It is calculated by taking the mean and subtracting the mean from it. This leaves us with an average that has been pulled away from its central point, or the mean. The variance can then be calculated by multiplying this difference by itself.
Variance =
variance =
So, we will take the mean (x) and subtract it from itself by x – x:
Variance =
This result is rounded to two decimal places (i.e., 0.5). Then, we multiply this value by itself again:
Variance =
and finally round this value down to one decimal place (i.e., 0.25).
Sorting Data by “Median” vs “All”
Sorting data by “Median” is not generally a good idea when you want to find p-values since it has no predictive power. Sorting data by “All” or “Mean” can help us know if one value is more likely than another in a dataset. The median is a useful statistic to describe how far an item or group falls in the middle of all values in a list, but it should be avoided when looking for p-values since it has no predictive power, meaning it cannot help us know if one value is more likely than another. And remember that StatCrunch calculates the median automatically, so sorting by “All” and “Median” will produce very different results.
Look at “Largest” and “Smallest”
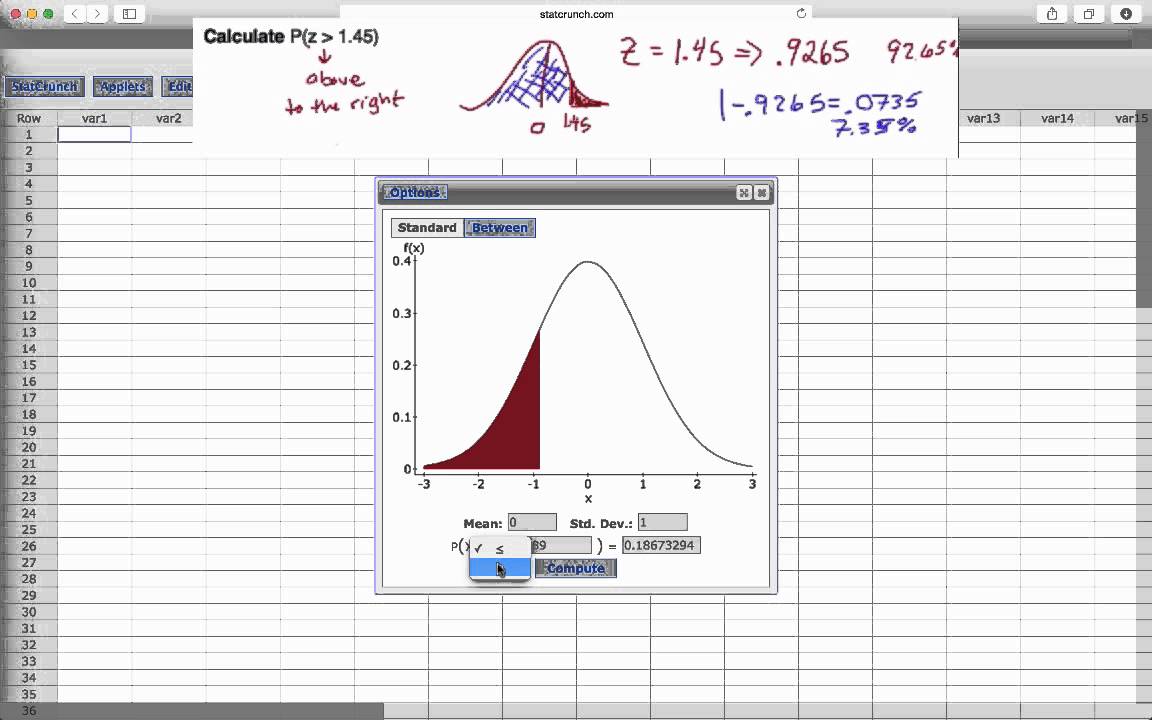
In order to find the P-value in StatCrunch, we are going to have to look at individual lists in the dataset and try to find outliers: observations that are much higher or lower than average.
One way is to use the “Largest” and “Smallest” statistics. These statistics give us an idea of where the median would fall, taking into account all values in between.
In this example, we can see that 3 observations had a p-value greater than 0.05, so they would be outliers.
Look at individual lists/lists of outliers
This is one of the most important tips in this blog. You want to make sure that you’re looking at individual lists or lists of outliers when analyzing your data. This will help you avoid misinterpreting what is going on and get the most out of your analysis.
4. Look for “less than” or “more than”. These statistics are useful to find observations that are smaller or larger than other values, respectively
5. Look for “At Least One” and “At Most One”. With these two statistics, you’ll be able to see which values exist in a list and how many observations there are in each group
6. Look for “More Than One”, “One”, and “Only One”. These three statistics help us find observations that are grouped by more than one value, one observation, and only one observation
7. Keep an eye out for outliers: look for observations that have different numbers of cases